
年化收益率近65%同济本科生用DRL算法训练了一个股票交易智能体操纵算法举办股票量化业务是当今金融墟市的一个紧张趋向。正在邦际象棋和围棋等诸众繁复的逛戏中,深度加强研习(DRL)智能体都得到了惊人的收效。深度加强研习的外面同样合用于股票墟市的量化决议。本文先容了同济大学阴谋机科学与本事系的上海市大学生立异创业操练设计精良项目:「基于深度加强研习的金融量化政策考虑」,解读了何如操练一个 A 股墟市的深度加强研习模子,以及回测的绩效体现。
正在该项目中,考虑者把股票墟市的汗青代价走势看作一个繁复的不全体新闻境况,而智能体必要正在这个境况中最大化回报和最小化危险。比拟于其他古板机械研习算法,深度加强研习的上风正在于对股票业务工作举办马尔可夫决议历程修模,没有将识别墟市情景和业务政策实行离开,更吻合伙票业务的特性。假使基于深度加强研习的量化政策考虑仍处于早期索求阶段,局限算法一经不妨正在特定的业务工作中显现出优越的收益。
探讨到业务墟市的随机性和互动性,考虑者将股票业务历程修模为如下图所示的马尔可夫决议历程(Markov Decision process, MDP),详细如下:
形态 s = [p, h, b],此中 p, h 均为 D 维向量,判袂代外股票代价和持股量,b 为而今余额(D 为正在墟市上探讨的股票数目)。
作为 a: D 维向量,代外对股票的操作。每只股票的可操作动作搜罗卖出、买入和持有,判袂导致持股量 h 的削减、填充和稳定。
: 代外股票正在形态 s 的业务政策,它性子上是作为 a 正在形态 s 的概率分散。
: 代外正在形态 s 实行作为 a,并正在后续形态以政策举办业务所能获取的渴望收益。
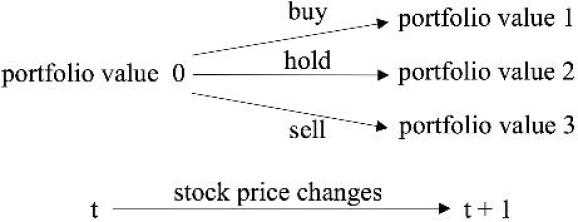
股票墟市的动态蜕变如下:正在 t 时候,智能体实行一个作为 a,能够是卖出、买入和持有,判袂导致持股量 h 的削减、填充和稳定。然后遵照持股量、余额的蜕变和股票代价的更新,从头阴谋股票代价
如下图所示,DDPG 采用 Actor-Critic 举措,它有一个政策搜集(Actor),一个代价搜集(Critic)。政策搜集支配智能体的活跃,它基于形态 s 做出作为 a。代价搜集不支配智能体,只是基于形态 s 给作为 a 打分,从而向导政策搜集做出改革。
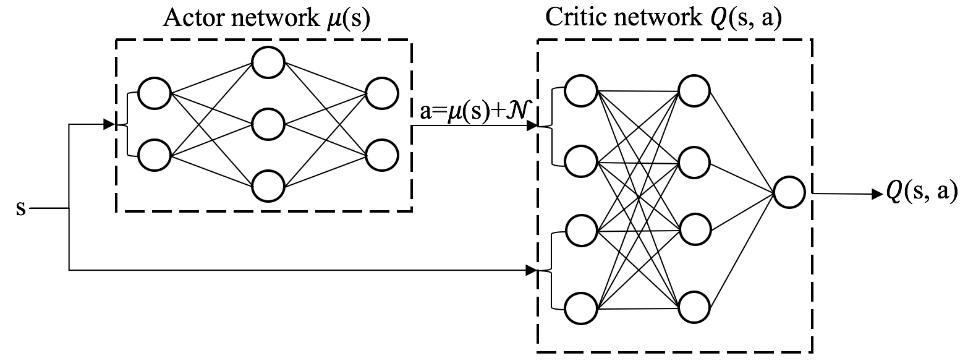
与 DQN 好似,DDPG 运用体会回放缓冲区(experience replay buffer) R 来存储搜集到的体会和更新模子参数,能够有用消重采样样本之间的相干性。为了搜集体会,每个时候,DDPG 智能体正在形态下选取作为
并存入 R 中。随后,从 R 中随机抽出 N 条体会,阴谋 TD target 并更新代价搜集参数,从而使得代价搜集对形态作为代价函数
的揣摸更精确。然后遵照代价搜集阴谋政策梯度并更新政策搜集的参数。下图对算法的细节做了周密的声明。

FinRL 是第一个显现出深度加强研习使用正在量化金融中雄伟潜力的 Python 开源框架。FinRL 供应了通用的构修模块,使政策拟订者不妨(1)将股票墟市数据集摆设为虚拟境况(2)操练深度神经搜集动作智能体(3)通过回测剖判智能体的业务体现。
起首,下载、装置并导入相干功用包,并通过 TushareDownloader 下载股票墟市数据集。然后举办数据预打点,重要是遵照原始股票数据阴谋各式金融本事性目标,这一步能够运用 FinRL 供应的 FeatureEngineer 类。
之后便是加强研习境况的界说,搜罗数据集的划分、形态空间巨细的阴谋以及初始金额、业务本钱等境况参数的设定。这一步会判袂界说操练和业务两个境况,必要运用 FinRL 供应的 StockTradingEnv 类。
境况搭修达成后,用搭修好的境况初始化 DRLAgent 类,获得一个智能体实例,并遵照必要给予智能体实例深度加强研习算法。目前 FinRL 框架中包蕴了 DDPG、A2C、PPO 等绝大无数主流深度加强研习算法,同时也支柱自界说算法。随后设定研习率等与模子操练相干的超参数,即可正在操练境况中发轫操练。
最终,让操练好的 DRLAgent 正在业务境况中业务,获得各岁月步下的投资组合代价和智能体的作为,再使用 FinRL 中集成的 pyfolio 自愿化回测器械就能获得年化收益率、夏普指数等一系列回测目标的数值和弧线图。
同济大学的本科生团队正悉力于基于深度加强研习的量化金融政策考虑,并一经运用 DDPG 算法正在我邦 A 股的汗青数据上得到了不错的成效。试验代码已正在 FinRL-Meta 开源。

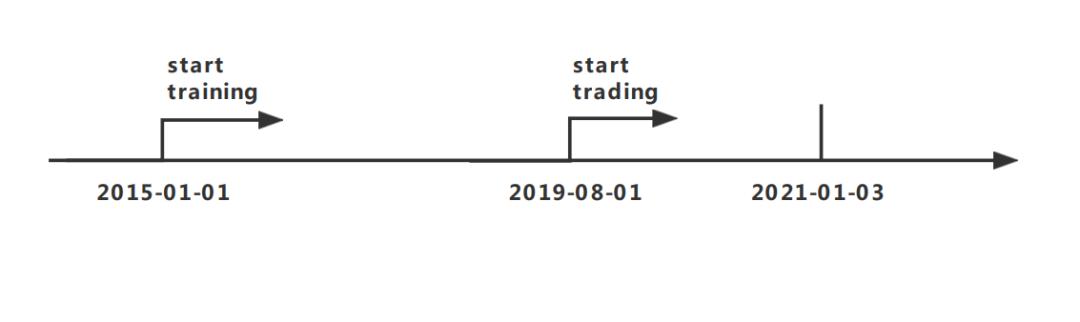
该考虑拣选了上证 50 中的 15 支动作业务股票,并运用 2015 年 1 月 1 日至 2021 年 1 月 3 日的汗青日代价来操练智能体并测试其体现。数据集通过开源的 Python 财经数据接口包 Tushare 获取。
试验搜罗三个阶段,即操练、验证和业务。正在操练阶段,起首运用 DDPG 算法天生一个操练有素的业务智能体。然后正在验证阶段调节枢纽参数,如 learning rate 和 episode 的巨细等。最终正在业务阶段,对操练获得的智能体的剩余才略举办评估。所以,全数数据集被分为两个局限,如下图所示。操练运用 2015 年 1 月 1 日至 2019 年 8 月 1 日的数据,测试运用 2019 年 8 月 1 日至 2021 年 1 月 3 日的数据。
该考虑运用三个目标来评估获得的结果: 最终投资组合代价、年化收益率和夏普比率。最终投资组合代价响应的是业务阶段收场时的投资组合代价。年化收益率是指投资组合每年的直给与益。夏普比率将收益和危险连合正在一道给出的评议。
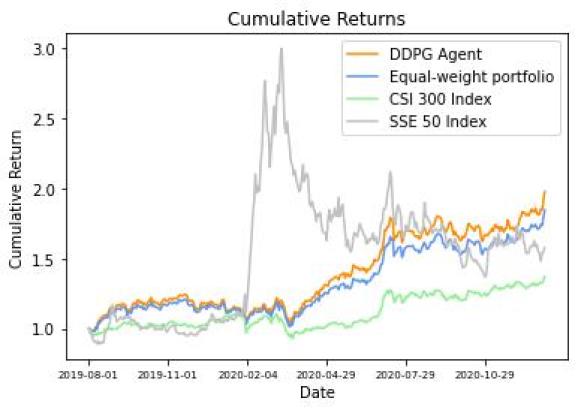
结果显示,智能体正在初始资金为 1000000 时,经历一年半的业务,最终投资组合代价为 1978179,年化收益率为 64.35%,夏普比率达 1.99。下图为累积收益率随岁月蜕变的弧线:验证集累积收益率蜕变图
NVIDIA Riva 是一个运用 GPU 加快,能用于急迅安放高机能会话式 AI 效劳的 SDK,可用于急迅开拓语音 AI 的使用序次。Riva 的策画旨正在轻松、急迅地拜望会话 AI 功用,开箱即用,通过少许浅易的号令和 API 操作就能够急迅构修高级其余对话式 AI 效劳。
原题目:《年化收益率近65%,同济本科生用DRL算法操练了一个股票业务智能体》






 ICP备8888888号
ICP备8888888号